最近遇到一个问题:
如何合并多个jupyter notebook的笔记为一个笔记文件?
经常用jupyter notebook写Python代码,看到这个需求不是想去找轮子而是想自己做解析和合并。通过深入文件格式去加深对jupyter notebook的了解。用jb 写代码有很多优势:交互式的编程体验、文档图表整合、扩展性强而且非常容易复现结果。从2017年开始,已有大量的北美顶尖计算机课程,开始完全使用Jupyter Notebook作为工具。如李飞飞的CS231N《计算机视觉与神经网络》课程,在16年时作业还是命令行Python的形式,但是17年的作业就全部在Jupyter Notebook上完成了。因此除了改主题安插件之外,探索更多的Jupyter Notebook用法和原理是有趣有用的。
用文本编辑器打开一个notebook文件,惊奇地发现不是乱码,说明不是直接存二进制格式而是文本格式,那就不用按数据块去解析了。如下图,熟悉的大括号和键值对让人想到json,仔细看果然是json,那读取就容易了,关键就是各个键的意义和数据组织。
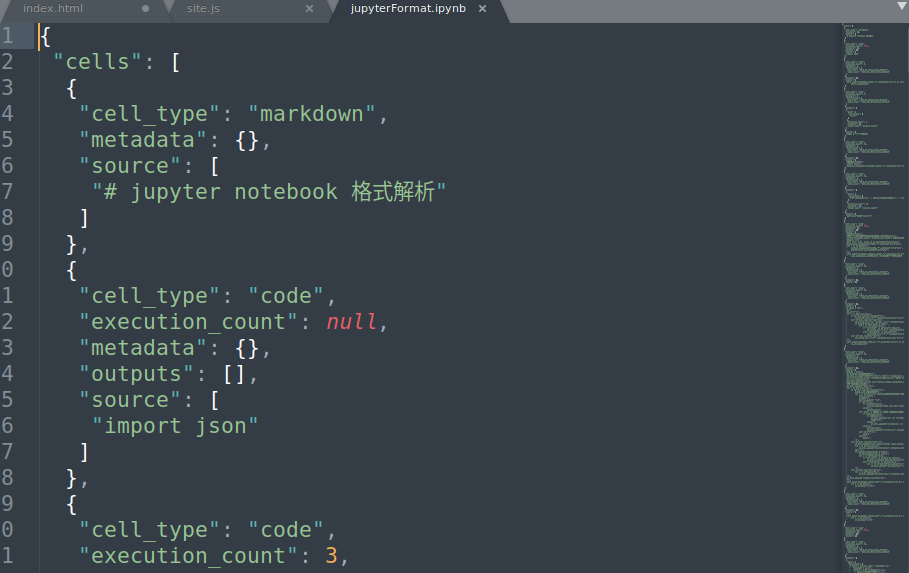
基础结构
Jupyter Notebook的文件是通过json格式存储和组织其中的数据的。JSON (JavaScript Object Notation)独立于编程语言,基础的结构就是{键1:值1,键2:值3} 这样的字典形式,值可以是数字、字符串、数组和字典。
Jupyter Notebook的顶层结构是一个键值对:{"metadata":{},"nbformat":4, "nbformat_minor":0, "cells":[] }
我们写代码的一个个格子对应的就在cells里,我们交互产生的数据都记录在cells键对应的列表里,如下图
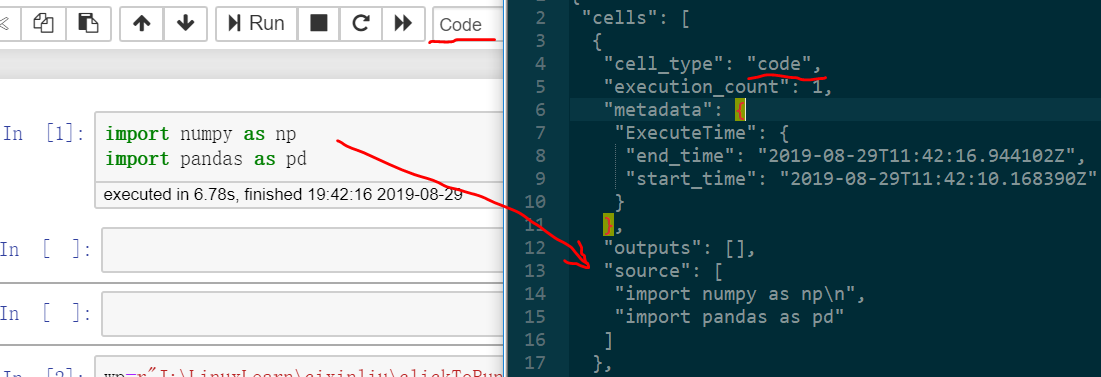
其他的键 像metadata是一些描述性的元数据,因此我们重点关注cells的列表。
内容部分
我们在里面写代码的一个个小块就是一个个cell,它整体也是一个字典,包含cell_type(内容类型)、source(我们输入的内容)、metadata(描述性的元数据);这三个键就构成了一个cell。如下面的思维导图,也可以结合上面 代码块区域示例 的图来理解。

其中execution_count 、output和attachments是不一定每个cell都存在的键,因此做解析是要有判断语句。
- cell_type有3种选择,code/markdown/raw,下面对这三种类型分别解析。
代码块通过cell的cell_type标识"cell_type"="code"
代码块里装的就是我们写的一行行代码,代码装在source键对应的列表里,source键对应的类型是列表list,列表里是字符串,一行代码是一个字符串。execution_count表示执行次数,对应我们前端能看到的In里的次数。
metadata记各种元数据,包括一些插件产生的数据,例如我安装了一个看执行时间的插件ExecuteTime,每次运行可以看执行耗时和最后一次执行的时间,这个数据也是会记录在ipynb文件里,对应的就装在metadata里,如果在一个没安装这个插件的环境里运行就不会读metadata的对应内容,可以说metadata给jupyter提供了很好的扩展性。
代码输出的内容在output对应的列表里。output的列表里装的不直接是数值或字符串,而是字典,output_type有多种可能,包括正常的代码输出的stream、execute_result,还有报错输出的error。
Markdown块是写报告和文档常用的cell,在前端会渲染出很好的效果,因为语义和格式就通过markdown本身约定的格式体现,对应记录的数据比代码块简单。不涉及输出所以不需要有output键,核心就是source和metadata。
无格式块的官方说法是叫 Raw NBConvert,对应cell_type的值是raw,因为是纯文本效果,在页面上不做特殊渲染,和markdown有的内容基本一致,核心就在source的字符串列表里。
以上内容整理为思维导图如下:
需求实现
基于以上我们对jupyter notebook文件结构的了解,就可以开工写合并多个ipynb文件为一个的代码了。
假设我们需要合并一个文件夹下的所有ipynb文件为一个,根据文件名的顺序组织。
我们首先读取得到需要合并的文件名的列表,然后通过json库读取ipynb文件的内容,因为我们写的代码、文字、代码输出结果这些都在cells里,而且顺序是cells列表里元素的顺序,所以我们合并cells里的内容就实现了这一需求。代码如下:
1 | import os |
因为nbformat等键是通用的,所以代码中直接用了第一个ipynb文件的nbformat值。一个合并的效果如下图(所用ipynb文件在https://github.com/QLWeilcf/LcfsPythonWork/tree/master/readingForDS 里可找到)。
关于合并多个ipynb文件这个需求有一个挺好的轮子是https://github.com/jbn/nbmerge 。
同样的思路我们可以根据一些条件对一个大的ipynb文件拆分为多个文件,例如按章拆分一个读书笔记(每个章节的特征是用了markdown语法,如 ## 第3章 用Python读写Excel文件)。
应用举例
了解了jupyter notebook的文件组织结构之后,除了合并ipynb文件还可以做哪些事情呢?其实我们可以造很多轮子。例如自己实现:
- 导出ipynb文件为py脚本文件:
- 导出ipynb文件为markdown文件;
- 导出为HTML文件;
导出ipynb文件为py脚本文件的代码示例如下:
1 | #ipynb 2 py |
【效果对比图】
因为有时候我们在Github上看ipynb格式的资料时,可能会加载不出来渲染的效果,这时候懂得了上面的jupyter notebook的文件组织结构后,我们可以从原始数据大致确定看的ipynb里有那些代码,输出的结果。
总结
总结这篇文章的内容:
- Jupyter Notebook有良好的文档图表整合能力和扩展性,已有大量的北美CS课程使用Jupyter Notebook作为编程环境;
- .ipynb文件是以json格式组织数据的;我们编写的代码、文本和输出存在cell列表里;
- 代码的顺序就是cell列表中元素顺序;
- 基于以上特点我们可以写代码合并和拆分notebook文件,还可实现ipynb文件转换为py、html格式文件。
以上内容自己整理了一个xmind脑图,获取思维导图文件和文中示例代码ipynb文件可在公众号后台回复 jupyter 获取。